Model
This document describes the classes in mtenn.model and their substituent parts, and the format of their inputs and outputs.
Model Blocks
Each class in mtenn.model is comprised of at least one of the following blocks:
Representation
The Representation block (mtenn.representation) is responsible for taking an input structure and learning an n-dimensional vector embedding.
In practice, this block is a thin wrapper around an existing model architecture, potentially with some ad hoc manipulation done to ensure the output is a vector rather than a single scalar value.
For more information on the models that are currently implemented in mtenn, see the Currently Implemented Models section.
For information on adding new models into the mtenn framework, see the guide on adding a new installable model.
Strategy
The Strategy block (mtenn.strategy) is responsible for taking any number of vectors, each output from a Representation block, and combining them into a \(\Delta g_{\mathrm{bind}}\) prediction in kT units.
Currently, the following Strategy blocks are implemented in mtenn:
Readout
The Readout block (mtenn.readout) is responsible for converting the \(\Delta g_{\mathrm{bind}}\) prediction output from a Strategy block from kT units into any arbitrary other unit.
Importantly, in contrast to the two previous blocks, this block doesn’t have any learned parameters.
This increases model portability, as it allows the same model to be trained on multiple different data types by only swapping out this last layer.
Combination
The Combination block (mtenn.combination) is responsible for combining multiple model predictions for the same compound into a single prediction.
The internal workings of these blocks are a bit complex, and a more in-depth explanation is given in the Combination page.
Currently, the following Combination blocks are implemented in mtenn:
Single-Pose Models
This section is a description of the mtenn.model.Model class (referred to as Model from here), which makes a prediction on a single input conformation.
The general data flow through a Model object is as depicted in the below diagram:
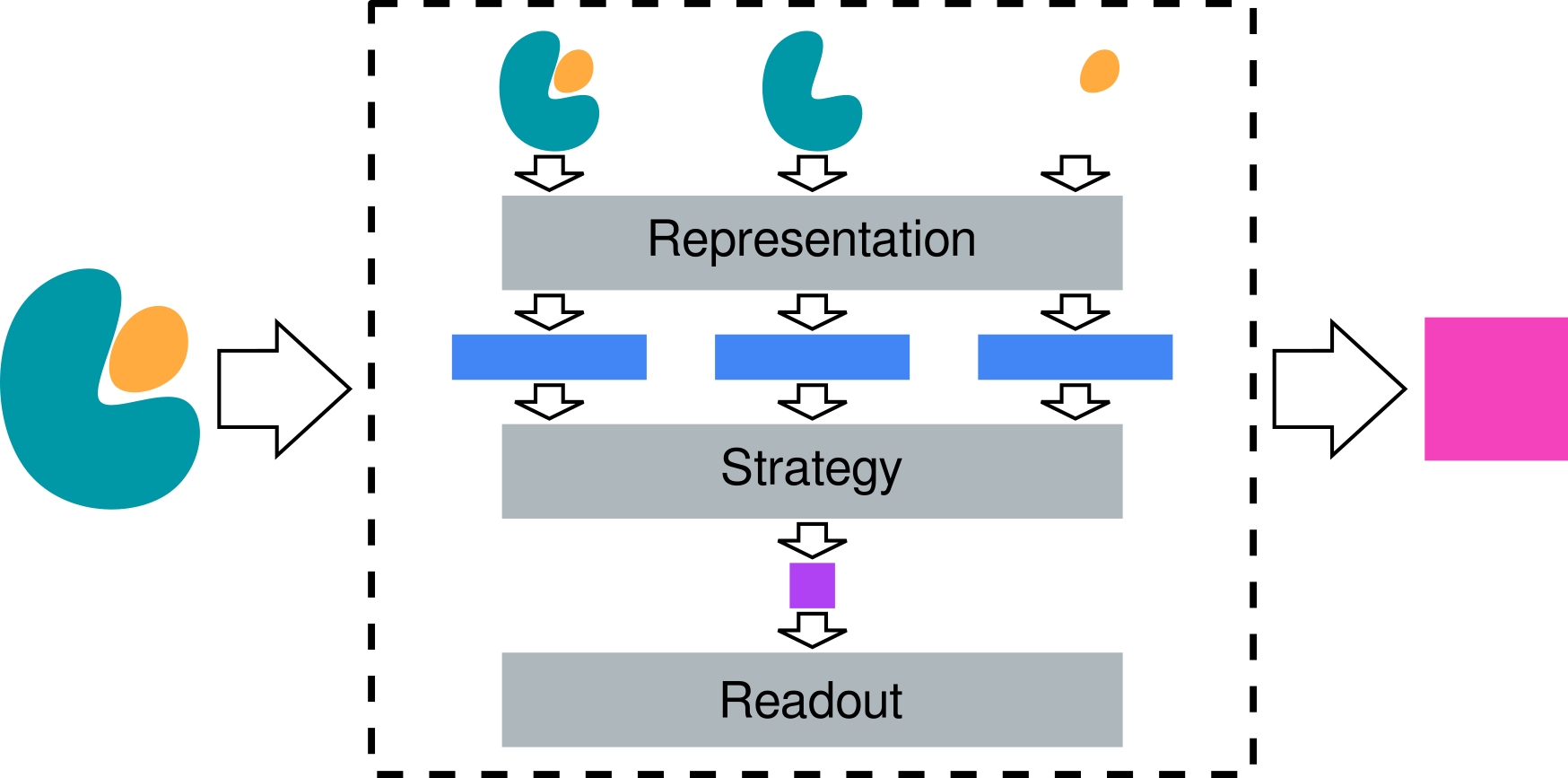
In text form this is:
The protein-ligand complex structure is passed to the
ModelInternally, the
Modelbreaks the structure into 3 sub-structures: the full complex, just the protein, and just the ligandEach of these sub-structures is individually passed to the
Representationblock to generate a total of 3 vector representationsAll 3 representations are passed to the
Strategyblock, where they are combined into a \(\Delta g_{\mathrm{bind}}\) prediction in implicit kT units(optional) The \(\Delta g_{\mathrm{bind}}\) prediction is passed to the
Readoutblock, where it is converted into whatever the final units are
Multi-Pose Models
This section is a description of the mtenn.model.GroupedModel class (GroupedModel from here), which makes a prediction on multiple input conformations.
The general data flow through a GroupedModel object is as depicted in the below diagram:
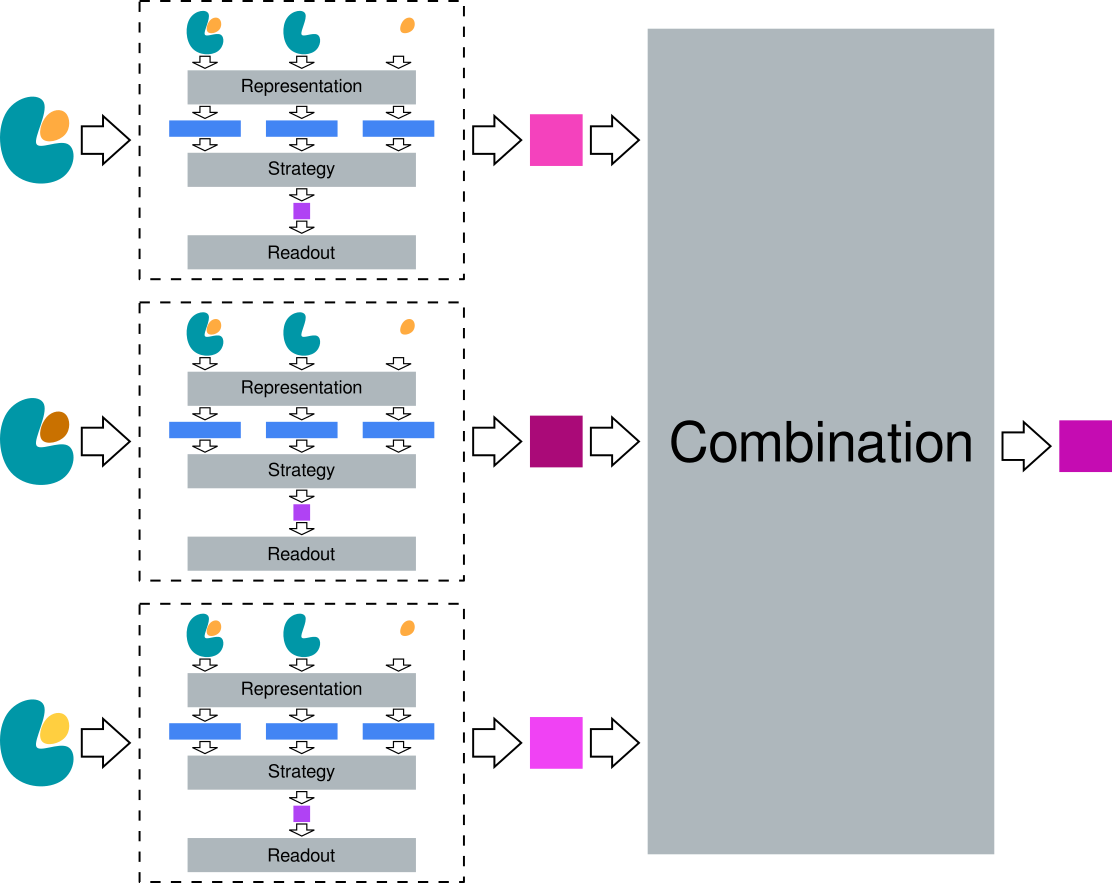
In text form this is:
Each input conformation is passed through the same
Modelobject to get a prediction for each individual conformationAll predictions are passed through a
Combinationblock to get an overall \(\Delta g_{\mathrm{bind}}\) prediction for the group of input poses(optional) The overall \(\Delta g_{\mathrm{bind}}\) prediction is passed to the
Readoutblock, where it is converted into whatever the final units are
Ligand-Only Models
This section is a description of the mtenn.model.LigandOnlyModel class (LigandOnlyModel from here), which makes a prediction based only on a ligand representation.
This class is mainly useful for 2D baseline models to compare the structure-based models against (eg ligand-only GNNs, fingerprint-based models, etc).
The general data flow through a LigandOnlyModel object is the same as for a Model, but the Representation block is responsible for generating the energy prediction from the input, and the Strategy block is simply the identity function.
Currently Implemented Models
Data Model
Input Data
Currently, all of the single-pose models in mtenn (Model and LigandOnlyModel) expect a dict object to be passed as their input.
The GroupedModel expects a list of these dicts, each one corresponding to a different input pose.
What keys each model expects in the dict is left to the implementation of that model in the conversion_utils module.
For more details on the data expected by each model, check that model’s docs page.
Output Data
To unify the outputs of all model types, all 3 models (Model, GroupedModel, and LigandOnlyModel) return two values: a scalar value that represents the model’s final prediction, and a list of values that represent the pre-Readout predictions of each input pose.
In the case of the single-pose models, this list will have exactly one element.
In the case of a multi-pose model, this list will have one element for each element in the list of input poses.